%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Visual Language Model
R1 V
R1-V is a project focused on enhancing the generalization capabilities of visual language models (VLMs). Using verified reward reinforcement learning (RLVR) technology, it significantly improves the generalization abilities of VLMs in visual counting tasks, particularly excelling in out-of-distribution (OOD) tests. The significance of this technology lies in its ability to efficiently optimize large-scale models at an extremely low cost (training costs as low as $2.62), offering new insights into the practical applications of visual language models. The project is based on improvements to existing VLM training methods, aiming to enhance model performance in complex visual tasks through innovative training strategies. Its open-source nature also makes it a vital resource for researchers and developers exploring and applying advanced VLM technologies.
AI Model
66.8K

Moondream AI
Moondream AI is an open-source visual language model with powerful multimodal processing capabilities. It supports various quantization formats such as fp16, int8, and int4, enabling GPU and CPU optimized inference across target devices like servers, PCs, and mobile devices. Key advantages include fast, efficient, and easy deployment, under the Apache 2.0 license that permits users to freely use and modify it. Moondream AI is positioned to provide developers with a flexible and efficient AI solution suitable for a wide range of applications requiring visual and language processing abilities.
AI Model
52.4K
Cogagent
CogAgent is a GUI agent based on visual language models (VLM) that facilitates bilingual (Chinese and English) cloud interaction through screenshots and natural language. CogAgent has made significant advancements in GUI perception, inference prediction accuracy, operational space integrity, and task generalization. The model has been applied in ZhipuAI's GLM-PC product, with the aim of aiding researchers and developers in advancing the research and application of GUI agents based on visual language models.
AI Model
59.3K
Deepseek VL2 Tiny
DeepSeek-VL2 is a series of advanced large-scale Mixture of Experts (MoE) visual language models, significantly improved compared to its predecessor, DeepSeek-VL. This model series demonstrates exceptional capabilities across various tasks, including visual question answering, optical character recognition, document/table/chart understanding, and visual localization. The DeepSeek-VL2 series consists of three variants: DeepSeek-VL2-Tiny, DeepSeek-VL2-Small, and DeepSeek-VL2, with 1.0B, 2.8B, and 4.5B active parameters, respectively. DeepSeek-VL2 achieves competitive or state-of-the-art performance compared to existing open-source dense and MoE-based models with similar or fewer active parameters.
AI Model
70.4K
POINTS Yi 1.5 9B Chat
POINTS-Yi-1.5-9B-Chat is a visual language model that incorporates the latest visual language model technologies along with innovations introduced by WeChat AI. The model features significant innovations in pre-training dataset filtering and Model Soup technology, allowing for substantial reductions in dataset size while enhancing model performance. It excels in multiple benchmark tests, marking an important advancement in the field of visual language models.
AI Model
45.3K
POINTS 1 5 Qwen 2 5 7B Chat
The latest update in the WePOINTS series features a large parameter count and robust performance, incorporating multiple innovative technologies and excelling in the OpenCompass leaderboard.
AI Model
42.8K
Opengvlab InternVL
InternVL is an AI visual language model focusing on image analysis and description. Utilizing deep learning technologies, it can understand and interpret image content, providing users with accurate image descriptions and analysis results. Key advantages of InternVL include high accuracy, rapid response times, and ease of integration. The technology is grounded in the latest AI research, aimed at enhancing the efficiency and precision of image recognition. Currently, InternVL offers a free trial, with pricing and service options customizable based on user needs.
Image Generation
47.2K
Qwen2 VL 7B
Qwen2-VL-7B is the latest iteration of the Qwen-VL model, representing a year of innovative advancements. It achieves state-of-the-art performance on visual understanding benchmarks, including MathVista, DocVQA, RealWorldQA, MTVQA, among others. The model can comprehend videos over 20 minutes long, providing high-quality support for video-based question answering, dialogue, and content creation. Additionally, Qwen2-VL supports multiple languages, including English, Chinese, and most European languages, as well as Japanese, Korean, Arabic, Vietnamese, and more. Updates to the model architecture include Naive Dynamic Resolution and Multimodal Rotary Position Embedding (M-ROPE), enhancing its multimodal processing capabilities.
AI Model
46.6K
Qwen2 VL 2B
Qwen2-VL-2B is the latest iteration of the Qwen-VL model, representing nearly a year's worth of innovations. The model has achieved state-of-the-art performance on visual understanding benchmarks including MathVista, DocVQA, RealWorldQA, and MTVQA. It can comprehend over 20-minute videos, providing high-quality support for video-based question answering, dialogue, and content creation. Qwen2-VL also supports multiple languages, including most European languages, Japanese, Korean, Arabic, Vietnamese, in addition to English and Chinese. Model architecture updates include Naive Dynamic Resolution and Multimodal Rotary Position Embedding (M-ROPE), which enhance its multimodal processing capabilities.
AI Model
48.0K
Paligemma 2
PaliGemma 2 is the second generation visual language model in the Gemma family, offering enhanced performance with added visual capabilities, allowing the model to see, understand, and interact with visual inputs, opening up new possibilities. Built on the high-performance Gemma 2 model, it offers various model sizes (3B, 10B, 28B parameters) and resolutions (224px, 448px, 896px) to optimize performance for any task. Moreover, PaliGemma 2 demonstrates leading performance in chemical formula recognition, score recognition, spatial reasoning, and generation of chest X-ray reports. It is designed to provide existing PaliGemma users with a convenient upgrade path, serving as a plug-and-play alternative that requires minimal code modifications for significant performance improvements.
AI Model
47.5K
Smolvlm
SmolVLM is a compact yet powerful visual language model (VLM) with 2 billion parameters, leading in efficiency and memory usage among similar models. It is fully open-source, with all model checkpoints, VLM datasets, training recipes, and tools released under the Apache 2.0 license. The model is designed for local deployment in browsers or edge devices, reducing inference costs and allowing for user customization.
AI Model
53.0K
Llava O1
LLaVA-o1 is a visual language model developed by the Yuan Group at Peking University, capable of spontaneous and systematic reasoning, similar to GPT-01. This model has outperformed others in six challenging multimodal benchmarks, including Gemini-1.5-pro, GPT-4o-mini, and Llama-3.2-90B-Vision-Instruct. LLaVA-o1 demonstrates its unique advantages in visual language modeling by solving problems through step-by-step reasoning.
Step-by-Step Reasoning
48.6K
Aquila VL 2B Llava Qwen
The Aquila-VL-2B model is a visual-language model (VLM) trained on the LLava-one-vision framework, utilizing the Qwen2.5-1.5B-instruct model as the language model (LLM) and the siglip-so400m-patch14-384 as the visual tower. This model was trained on the self-constructed Infinity-MM dataset, which contains approximately 40 million image-text pairs, combining open-source data collected from the internet with synthetic instruction data generated using open-source VLM models. The open-source nature of the Aquila-VL-2B model aims to advance multimodal performance, especially in the integrated processing of image and text.
AI Model
51.6K
Visrag
VisRAG is an innovative retrieval-augmented generation (RAG) process based on visual language models (VLMs). Unlike traditional text-based RAG, VisRAG embeds documents directly as images through a VLM, which enhances the generative capabilities of the VLM. This method maximizes the retention of data information from the original documents, eliminating the information loss introduced during parsing. The application of the VisRAG model on multimodal documents demonstrates its strong potential in information retrieval and enhanced text generation.
Research Equipment
52.7K

Qwen2 VL
Qwen2-VL is the latest generation visual language model developed on the Qwen2 framework, featuring multilingual support and powerful visual comprehension capabilities. It can process images of varying resolutions and aspect ratios, understand long videos, and can be integrated into devices such as smartphones and robots for automation. It has achieved leading performances on multiple visual understanding benchmarks, particularly excelling in document comprehension.
AI Model
55.5K
Fresh Picks
Internlm XComposer 2.5
InternLM-XComposer-2.5 is a multifunctional large visual language model that supports long context input and output. It excels in various text-image understanding and generation applications, achieving performance comparable to GPT-4V while utilizing only 7B parameters for its LLM backend. Trained on 24K interleaved image-text context, the model seamlessly scales to 96K long context through RoPE extrapolation. This long context capability makes it particularly adept at tasks requiring extensive input and output context. Furthermore, it supports ultra-high resolution understanding, fine-grained video understanding, multi-turn multi-image dialogue, web page creation, and writing high-quality text-image articles.
AI Model
73.4K
VILA
VILA is a pre-trained visual language model (VLM) that achieves video and multi-image understanding capabilities through pre-training with large-scale interleaved image-text data. VILA can be deployed on edge devices using the AWQ 4bit quantization and TinyChat framework. Key advantages include: 1) Interleaved image-text data is crucial for performance enhancement; 2) Not freezing the large language model (LLM) during interleaved image-text pre-training promotes context learning; 3) Re-mixing text instruction data is critical for boosting VLM and plain text performance; 4) Token compression can expand the number of video frames. VILA demonstrates captivating capabilities including video inference, context learning, visual reasoning chains, and better world knowledge.
AI Model
84.2K

Minigemini
Mini-Gemini is a multimodal visual language model supporting a series of dense and MoE large language models ranging from 2B to 34B. It possesses capabilities for image understanding, reasoning, and generation. Based on LLaVA, it utilizes dual vision encoders to provide low-resolution visual embeddings and high-resolution candidate regions. It employs patch-level information mining to perform patch-level mining between high-resolution regions and low-resolution visual queries, fusing text and images for understanding and generation tasks. It supports multiple visual understanding benchmark tests, including COCO, GQA, OCR-VQA, and VisualGenome.
AI image generation
153.5K

Spatialvlm
SpatialVLM is a visual language model developed by Google DeepMind that can understand and reason about spatial relationships. Trained on massive synthetic datasets, it has acquired the ability to perform quantitative spatial reasoning intuitively, like humans. This not only improves its performance on spatial VQA tasks but also opens up new possibilities for downstream tasks such as chain-of-thought spatial reasoning and robot control.
AI Model
60.4K
Mousi
MouSi is a multimodal visual language model designed to address the challenges faced by current large-scale visual language models (VLMs). It utilizes an integrated expert approach, synergistically combining the capabilities of individual visual encoders for tasks like image-text matching, OCR, and image segmentation. The model introduces a fusion network to unify the outputs from different visual experts and bridge the gap between image encoders and pre-trained LLMs. Furthermore, MouSi explores diverse position encoding schemes to effectively tackle the issues of position encoding redundancy and length limitations. Experimental results demonstrate that VLMs with multiple experts exhibit superior performance compared to isolated visual encoders, achieving significant performance gains as more experts are integrated.
AI Model
58.2K
Internlm XComposer2
InternLM-XComposer2 is a leading visual language model proficient in free-form text-to-image synthesis and understanding. It not only comprehends traditional visual languages but also adeptly constructs interwoven text-image content from various inputs, including outlines, detailed text specifications, and reference images, enabling highly customizable content creation. InternLM-XComposer2 proposes a Partial LoRA (PLoRA) method, specifically applying additional LoRA parameters to image tokens to preserve the integrity of pre-trained language knowledge, achieving a balance between precise visual understanding and literary-quality text generation. Experimental results demonstrate that InternLM-XComposer2, based on InternLM2-7B, excels in generating high-quality long-form multimodal content and exhibits outstanding visual language understanding performance in various benchmark tests. It significantly surpasses existing multimodal models and even rivals or surpasses GPT-4V and Gemini Pro in some evaluations, highlighting its exceptional capabilities in the field of multimodal understanding. InternLM-XComposer2 models, with 7B parameters, are publicly available on https://github.com/InternLM/InternLM-XComposer.
AI image generation
129.7K
Chexagent
CheXagent is a chest X-ray interpretation tool based on visual language foundation models. It leverages clinical large language models to parse radiology reports, visual encoders to represent X-ray images, and designs a network to bridge the visual and language modalities. Additionally, CheXagent introduces CheXbench, a new benchmark designed to systematically evaluate the performance of visual language foundation models on eight clinically relevant chest X-ray interpretation tasks. Through extensive quantitative evaluation and qualitative review by five expert radiologists, CheXagent outperforms previously developed general-purpose and medical domain foundation models on CheXbench tasks.
AI medical health
64.6K
Vary
Vary is an official code implementation for large-scale visual language models. It enhances model performance by expanding the visual vocabulary. The model boasts strong image understanding and language generation capabilities, applicable across multiple domains.
AI image generation
85.8K
Pali3
Pali3 is a visual language model that generates desired answers by encoding images and passing them along with queries to a encoder-decoder Transformer. The model undergoes several stages of training, including unimodal pre-training, multimodal training, resolution increase, and task specialization. Pali3's main functions include image encoding, text encoding, and text generation. It is suitable for tasks like image classification, image captioning, and visual question answering. Pali3's advantages lie in its simple model structure, good training results, and fast speed. This product is priced at free and open-source.
AI image detection and recognition
85.6K
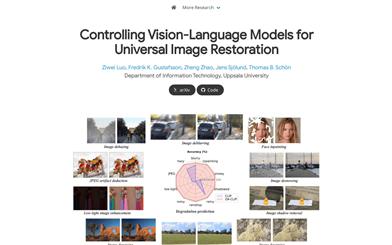
DA CLIP
DA-CLIP is a degradation-aware visual language model that can serve as a general framework for image recovery. It trains an additional controller to enable a fixed CLIP image encoder to predict high-quality feature embeddings, which are then integrated into the image recovery network, leading to high-fidelity image reconstruction. The controller also outputs degradation features that match the true corruption of the input, providing a natural classifier for different degradation types. DA-CLIP is further trained on mixed degradation datasets, improving performance on specific degradation and unified image recovery tasks.
AI image generation
73.1K
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
43.1K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
44.7K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
42.5K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
43.3K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
42.5K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
42.8K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.7K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M